
Large Language Models (LLMs) are revolutionizing natural language processing (NLP) by enabling machines to understand and generate human-like text (or even beyond). In this article, we explore key LLMs, their capabilities, and their impact on various applications.
Intro to LLMs
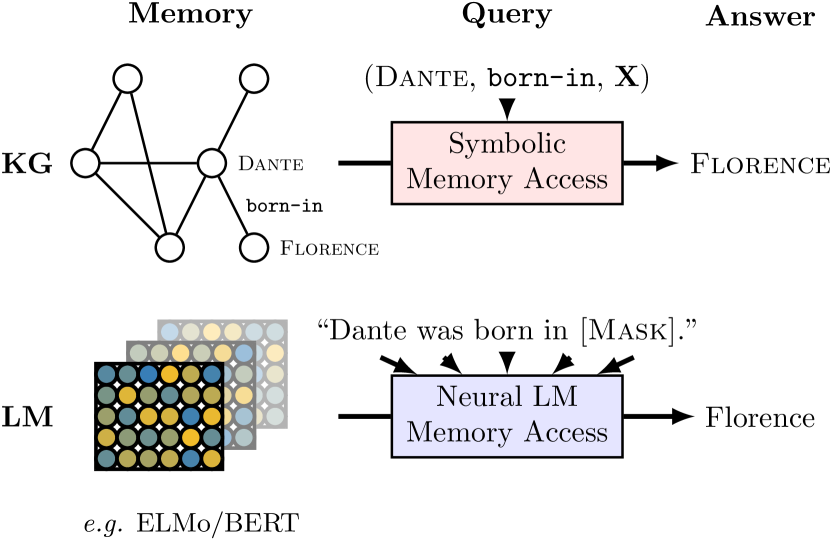
Language models (LMs) are computational models with the capability to understand and generate human language. Pretrained high-capacity language models such as ELMo1 and BERT2 became critical to NLP. Studies has shown that vast amounts of linguistic knowledge stored among parameters of these models3.
General Language Model Pretraining with Autoregressive Blank Infilling (GLM)
From ACL 2022-05. Before GLM, there have been various types of pretraining architectures including autoencoding models (e.g., BERT, learn left-to-right language model), autoregressive models (e.g., GPT), and encoder-decoder models (e.g., T5).
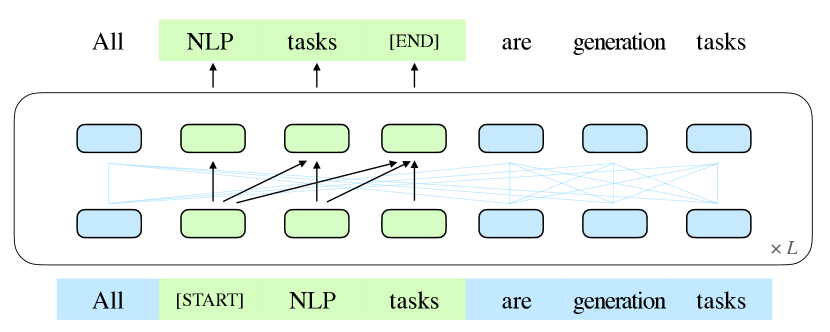
Autoregressive models, such as GPT, learn left-to-right language models. They excel in long-text generation and show few-shot learning capabilities when scaled to billions of parameters. However, their unidirectional attention mechanism may not fully capture dependencies between context words in natural language understanding (NLU) tasks.
Autoencoding models, like BERT, learn bidirectional context encoders via denoising objectives, such as Masked Language Model (MLM). These models produce contextualized representations suitable for NLU tasks but are not directly applicable for text generation.
Encoder-decoder models use bidirectional attention for the encoder, unidirectional attention for the decoder, and cross attention between them. They are typically deployed in conditional generation tasks, such as text summarization and response generation. However, they require more parameters to match the performance of BERT-based models.
None of these pretraining frameworks is flexible enough to perform competitively across all NLP tasks. Previous works have attempted to unify different frameworks through multi-task learning, but a simple unification cannot fully inherit the advantages of both frameworks due to their differing objectives.
A pretraining framework named GLM (General Language Model) is proposed, based on autoregressive blank infilling. GLM randomly blanks out continuous spans of tokens from the input text, following the idea of autoencoding, and trains the model to sequentially reconstruct these spans, following the idea of autoregressive pretraining. While blank filling has been used in T5 for text-to-text pretraining, GLM introduces two improvements: span shuffling and 2D positional encoding.4
Generative Pre-trained Transformer, GPT-3, NeurIPS 2020
From Language Models are Few-Shot Learners. Natural Language Processing (NLP) have seen a shift towards pre-trained language models that are increasingly task-agnostic and flexible.
- A single-layer word vectors were used.5,6
- Followed by RNNs with multiple layers.7,8
- Transformer models 9 that can be fine-tuned directly on specific tasks.2,10
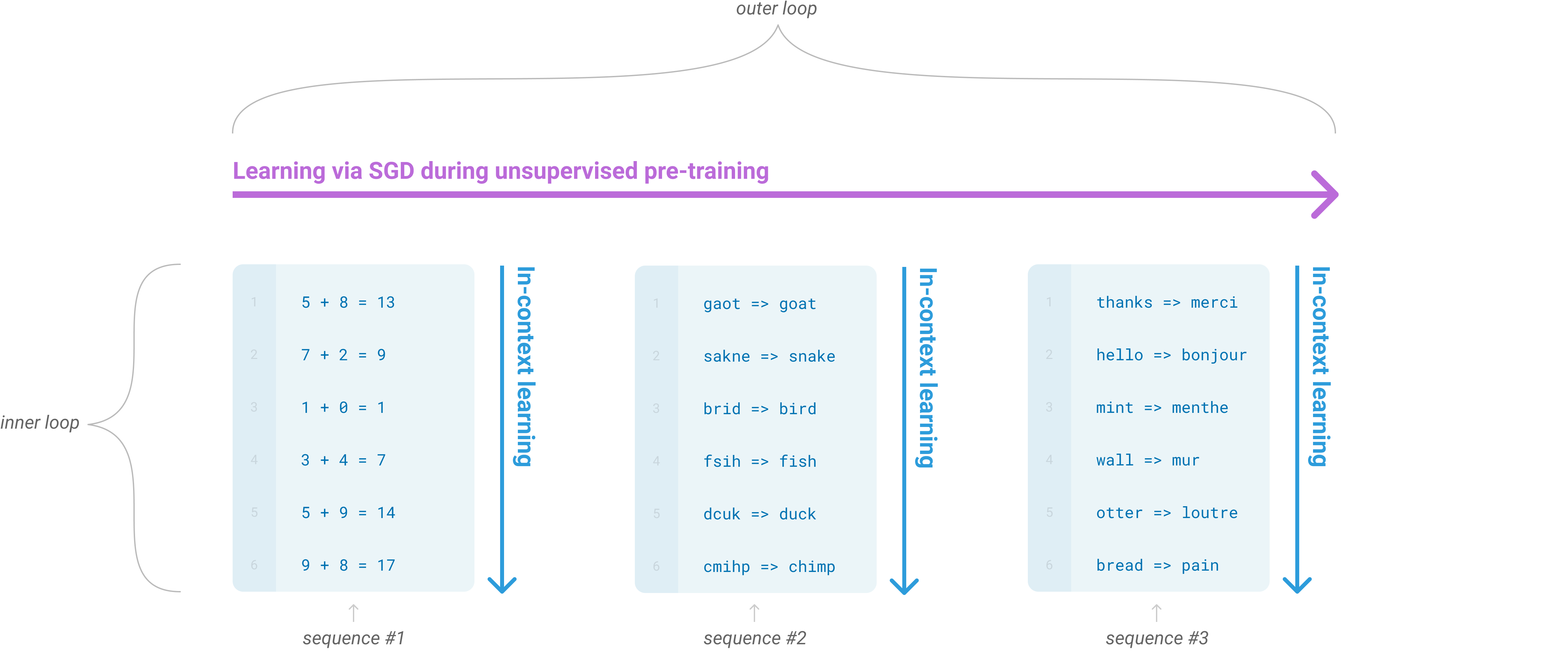
in-context learning is used to describe the inner loop of such processes.
The need for large, task-specific datasets for fine-tuning limits the applicability of language models.
InstructGPT, NeurIPS 2022
When LLMs generate outputs that are untruthful, toxic, or simply not helpful to the user, they are not aligned with the user. LMs can be aligned with user intents by fine-tuning with human feedback. PPO plays a big part in the process.
Mistral 7B
Mistral 7B takes a significant leap in balancing the goals of getting high performance while keeping large language models efficient. Mistral 7B is based on a transformer architecture, sharing ssome similarity to Llama, while introducing a few changes including
- Sliding Window Attention, SWA
- to attend information beyond the window size \(W\), a hidden state in position \(i\) of layer \(k\), \(h_i\), attends to ALL hidden states from previous layer with positions between \(i - W\) and \(i\).
- Rolling Buffer Cache
- A fixed attention span results in a fixed cache size \(W\), reduces the cache memory usage while not impacting model quality.
- Pre-fill and Chunking
- The prompt is known in advance, and we can pre-fill the \((k, v)\) cache with the prompt.
Mistral 7B uses a byte-level BPE (Byte-Pair Encoding) tokenizer, which is similar to what models like LLaMA use. It is trained using the standard next-token prediction objective, where the model learns to predict the next token in a sequence.
Mistral 7Bx8
Mistral 7B×8 is based on a transformer architecture, a common framework for large language models. The “7B” refers to the model having approximately 7 billion parameters. However, “7B×8” indicates that there are 8 different expert models, each with 7 billion parameters, which are combined in a Mixture of Experts (MoE) framework.
Some Techniques implemented in LLM
Mixture of Experts (MoE)
Sparse training is an active area of research and engineering (Gray et al., 2017; Gale et al., 2020). The original Mixture of Experts (MoE) model routes input tokens to a subset of experts, typically the top-k experts, using a softmax-based gating mechanism.
MoE uses a gating mechanism that routes different inputs to different “experts”. The gating network assigns each input 𝑥 a probability distribution over the experts. The gate outputs a sparese probability distribution \(p(x)\) from a set of experts \({E_i}_{i=1}^N\). \(p_i(x)\) is the probability of choosing expert \(i\) for input \(x\)
Switch Transformers takes
KV (Key-Value) cache
The KV (Key-Value) cache is a memory optimization technique used to accelerate inference by caching the key and value tensors from the attention mechanism across different layers, critical for efficiently processing long sequences without recalculating the same values repeatedly.
The attention mechanism in transformers can be described mathematically as: Attention(Q,K,V)=softmax(QKTdk)V
Encoders and Decoders in transformer models
In the transformer encoder, the self-attention mechanism allows each token in the input sequence to attend to all other tokens in the same sequence. The decoder in a transformer model uses two attention mechanisms: self-attention and encoder-decoder attention (sometimes called cross-attention).
Chain-of-Thought (CoT) Prompting
By asking LLM to solve complex reasoning tasks in a step-wise manner, CoT enhances the reasoning abilities of Large Language Models (LLMs).
Knowledge Distillation
Knowledge distillation, introduced in Distilling the Knowledge in a Neural Network, transfers knowledge from a large model to a smaller one (large models may have large capacity but not fully utilized).

Data-efficient Image Transformer (DeiT)
A DeiT is a type of Vision Transformer (ViT) for image classification tasks, by
token distillation via a teacher-student strategy on ImageNet (10M+). Work before that (ViT for classification uses a private labelled image dataset JFT-300M)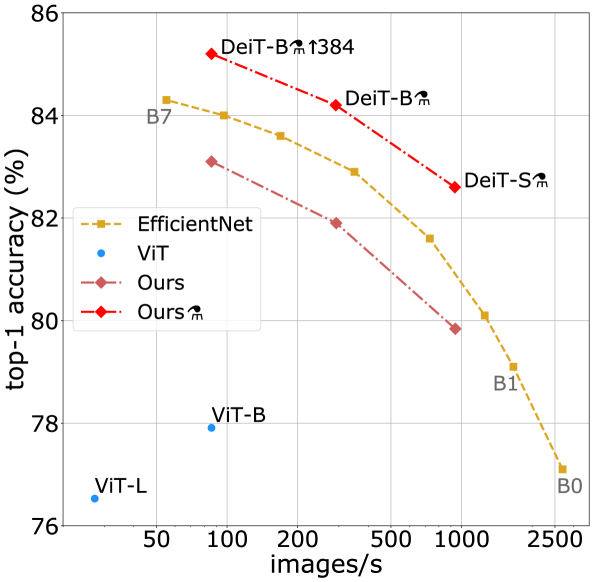
@inproceedings{peters2018deep, title={Deep Contextualized Word Representations}, author={Peters, Matthew E and Neumann, Mark and Iyyer, Mohit and Gardner, Matt and Clark, Christopher and Lee, Kenton and Zettlemoyer, Luke}, booktitle={Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)}, pages={2227--2237}, year={2018} } ↩︎
@article{devlin2018bert, title={Bert: Pre-training of deep bidirectional transformers for language understanding}, author={Devlin, Jacob}, journal={arXiv preprint arXiv:1810.04805}, year={2018} } ↩︎ ↩︎
@inproceedings{tenneyyou, title={What do you learn from context? Probing for sentence structure in contextualized word representations}, author={Tenney, Ian and Xia, Patrick and Chen, Berlin and Wang, Alex and Poliak, Adam and McCoy, R Thomas and Kim, Najoung and Van Durme, Benjamin and Bowman, Samuel R and Das, Dipanjan and others}, booktitle={International Conference on Learning Representations} } ↩︎
@inproceedings{du2022glm, title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling}, author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie}, booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, pages={320--335}, year={2022}} ↩︎
@inproceedings{pennington2014glove, title={Glove: Global vectors for word representation}, author={Pennington, Jeffrey and Socher, Richard and Manning, Christopher D}, booktitle={Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)}, pages={1532--1543}, year={2014} } ↩︎
@article{mikolov2013efficient, title={Efficient estimation of word representations in vector space}, author={Mikolov, Tomas}, journal={arXiv preprint arXiv:1301.3781}, year={2013} } ↩︎
@article{dai2015semi, title={Semi-supervised sequence learning}, author={Dai, Andrew M and Le, Quoc V}, journal={Advances in neural information processing systems}, volume={28}, year={2015} } ↩︎
@inproceedings{peters2018dissecting, title={Dissecting Contextual Word Embeddings: Architecture and Representation}, author={Peters, Matthew E and Neumann, Mark and Zettlemoyer, Luke and Yih, Wen-tau}, booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing}, pages={1499--1509}, year={2018} } ↩︎
@article{vaswani2017attention, title={Attention is all you need}, author={Vaswani, Ashish}, journal={arXiv preprint arXiv:1706.03762}, year={2017} } ↩︎
@article{radfordimproving, title={Improving Language Understanding by Generative Pre-Training}, author={Radford, Alec and Narasimhan, Karthik and Salimans, Tim and Sutskever, Ilya} } ↩︎