
Intro
Multimodal machine learning combines different types of data, mimicking human perception. This approach is being applied in healthcare, robotics, and multimedia, where diverse information must be processed. Challenges has been faced by researchers in integrating various data types, as models are required to handle different inputs while maintaining coherence. Despite difficulties, multimodal learning’s potential in areas like autonomous driving1 and human-computer interaction2 has been widely recognized.
Huge credit to Liang et al., 2022, a lot of figures are from (except for noted elsewhere)3
Rapid advancements in multimodal research have created challenges in:
- Recognizing consistent patterns across past and current studies.
- Identifying the fundamental unresolved issues in this area of study.
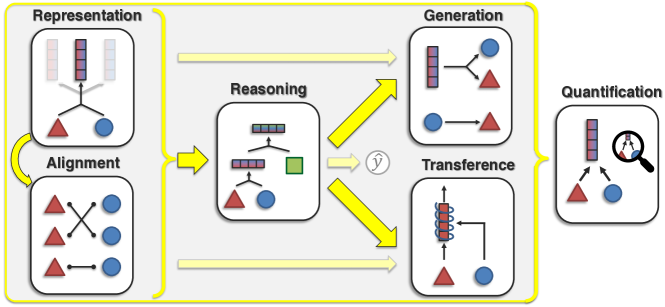
Multimodal Research
Modality refers to a way in which a natural phenomenon is perceived or expressed. Multimodal has multiple involved modalities. Modalities sits along a spectrum from raw (closer to a sensor) to abstract (further away from sensors, down the data processing pipelines). In a multimodal computational study, each entity is heterogeneous but interconnected.
Representation
Representation is about combining different types of data. Are heterogeneity and interconnections learnable during the process?
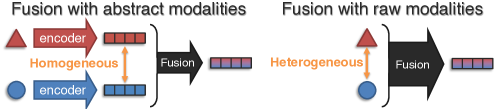
- Representation Fusion: Mixing information from different sources, effectively reducing separate representation.
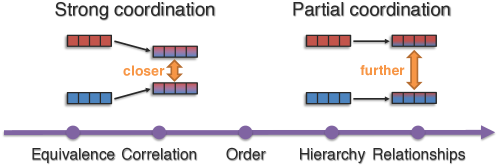
- Representation Coordination: Swapping information between sources to improve understanding
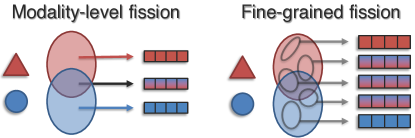
- Representation Fission: Breaking down information into smaller, separate parts
Alignment
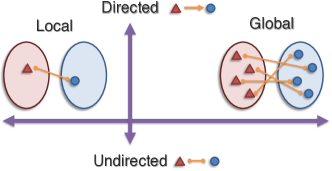
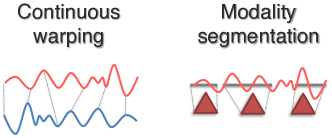
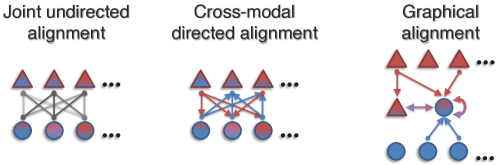
Alignment is about finding connections between different types of modality elements.
- Discrete Alignment: Linking specific pieces of (discrete) data and identify their connections.
- Continuous Alignment: For modality elements are NOT already segmented and discretized, methods based on
warpingandsegmentationhave been proposed. - Contextualized Representations: Learning how different types of data interact to obtain better representations.
Reasoning
Reasoning means composing knowledge and using information to solve problems, likely through multiple inferential steps.
- Structure Modeling: Understanding how the problem is set up and how the reasoning occurs.
- Intermediate Concepts: Breaking the problem into steps.
- Inference Paradigms: Figuring out how to reach conclusions (abstract concepts are inferred from individual multimodal evidence).
- External Knowledge: Using outside information to help.
Generation
This means creating new data (raw modalities) through a generative process.
- Summarization: Summing up important points from lots of data.
- Translation: Changing data from one type to another.
- Creation: Making new data that fits together well.
Transference
This is about knowledge transfer, from one type of modality to help with another.
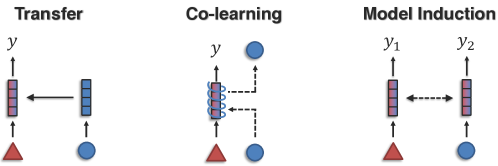
- Cross-modal transfer: Using what we know about one type of data to understand another. Readily available labeled or unlabeled data is used in secondary modalities to develop robust models. These models are then adapted or fine-tuned for tasks involving the primary modality, effectively transferring knowledge across different data types.
- Multimodal Co-learning: Sharing information between different types of data by sharing intermediate representation spaces between both modalities.
- Model Induction: Keeping different types of data/training separate but still sharing information (Model induction uses separate algorithms for different data views. Each algorithm’s results help label new data for the other view, expanding its training set. This transfers information across views through predictions, not shared spaces.)
Quantification
Studying how all of above works by empirical and theoretical analysis of multimodal models. This study aims to enhance understanding, leading to improvements in model robustness, interpretability, and real-world reliability.
- Dimensions of Heterogeneity: How different types of data are unique (understand the dimensions of heterogeneity)
- Modality Interconnections: How different types of data connect and interact
- Multimodal Learning Process: The challenges of working with heterogeneous data
Some tools / studies
Visual
Gradient-weighted Class Activation Mapping (Grad-CAM)
The Class Activation Mapping (CAM) approach [CVPR 2016] modifies image classification CNN architectures by replacing fully-connected (FC) layers with convolutional layers and global average pooling to achieve class-specific feature maps.
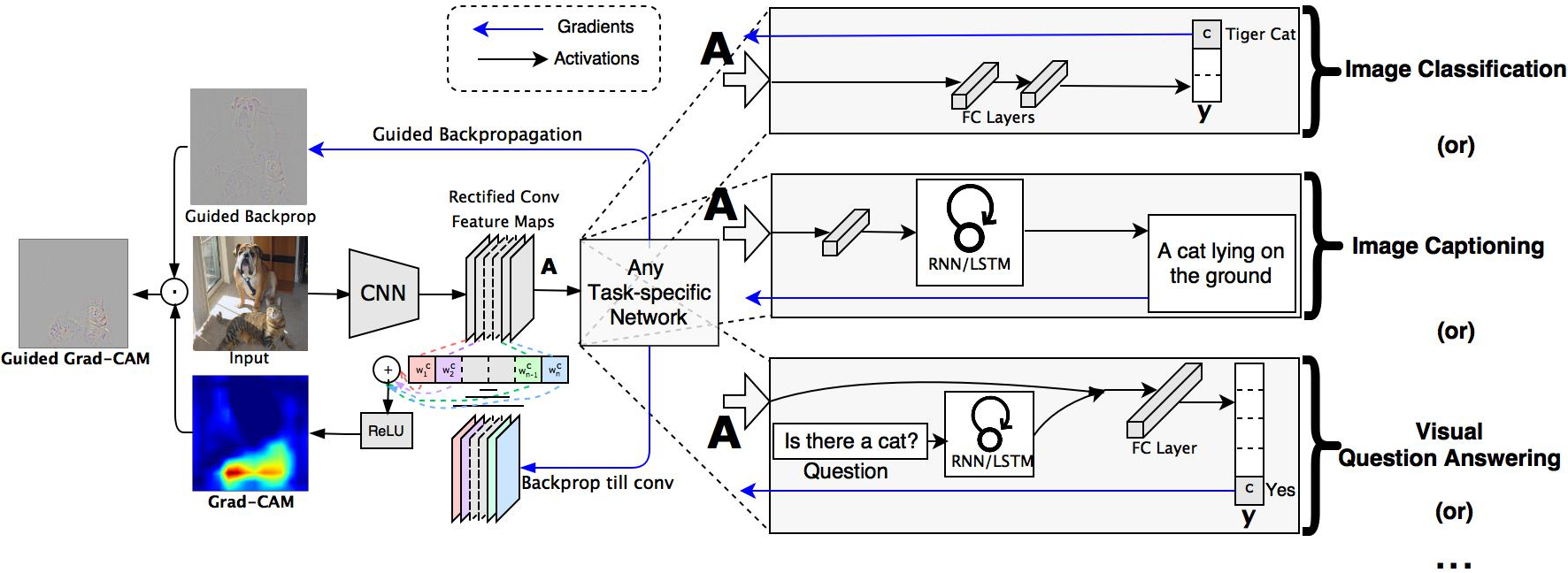
ICCV 2017, Grad-CAM uses gradients of any target concept (i.e. ‘dog’ in a classification network or a sequence of words in captioning network) flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept4. Grad-CAM uses the gradient information flowing into the last convolutional layer of the CNN to assign importance values to each neuron for a particular decision of interest.
{@article{xiao2020multimodal, title={Multimodal end-to-end autonomous driving}, author={Xiao, Yi and Codevilla, Felipe and Gurram, Akhil and Urfalioglu, Onay and L{\'o}pez, Antonio M}, journal={IEEE Transactions on Intelligent Transportation Systems}, volume={23}, number={1}, pages={537--547}, year={2020}, publisher={IEEE} }} ↩︎
@article{muhammad2021comprehensive, title={A comprehensive survey on multimodal medical signals fusion for smart healthcare systems}, author={Muhammad, Ghulam and Alshehri, Fatima and Karray, Fakhri and El Saddik, Abdulmotaleb and Alsulaiman, Mansour and Falk, Tiago H}, journal={Information Fusion}, volume={76}, pages={355--375}, year={2021}, publisher={Elsevier} } ↩︎
@article{liang2022foundations, title={Foundations and Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions}, author={Liang, Paul Pu and Zadeh, Amir and Morency, Louis-Philippe}, journal={arXiv preprint arXiv:2209.03430}, year={2022} } ↩︎
@inproceedings{selvaraju2017grad, title={Grad-cam: Visual explanations from deep networks via gradient-based localization}, author={Selvaraju, Ramprasaath R and Cogswell, Michael and Das, Abhishek and Vedantam, Ramakrishna and Parikh, Devi and Batra, Dhruv}, booktitle={Proceedings of the IEEE international conference on computer vision}, pages={618--626}, year={2017} } ↩︎